
数据储存概述
类型大小
| 类型 | 长度(按位算) | 最小值 | 最大值s |
|---|---|---|---|
| signed char | 8 | -128 | 127 |
| unsigned char | 8 | 0 | 255 |
| short | 16 | -32,768 | 32,767 |
| unsigned short | 16 | 0 | 65,535 |
| int | 32 | -2,147,483,648 | 2,147,483,647 |
| unsigned int | 32 | 0 | 4,294,967,295 |
| long | 32 | -2,147,483,648 | 2,147,483,647 |
| unsigned long | 32 | 0 | 4,294,967,295 |
| long long | 64 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
| unsigned long long | 64 | 0 | 18,446,744,073,709,551,615 |
补码
char类型默认为带符号类型并且占用1个字节。short类型占用2字节,int类型占用4字节。long型占4字节,long long型占8字节。
-15
1 | 0000 1111 15的标准二进制表示 |
溢出类型
向上溢出
1 | unsigned int a; |
0x2000 0020+0xE000 0000 = 0x1 0000 0040 无法被变量a容纳。当一个算术运算的结果值大于最大可能的表示数值时,我们就称他为数字溢出条件。

向下溢出
1 | unsigned int a; |
这个程序将 a 减去1,a的初始值为0,因此运算结果理论上为-1,但它不能被 a 容纳因为它小于了 a 的最小可能值0.这个结果被称为数字下溢条件。

案例分析
溢出
无符号整型使用不当漏洞
这种漏洞的原理我们上面已经说过了,在此就只提一下64位下的构造的思路:
- 确定缓冲区写入操作的长度参数所使用的数据类型的位数:n byte
- 确定需要绕过的长度检查的逻辑处所用的数据类型的位数:N byte
- 构造总长度为N byte,低n byte置为0其余各位元组全置为ff,记作r
- R = r|<实现溢出攻击所需的长度>,R即为最初输入的长度值
下面的代码来自OpenSSH 3.1问答认证(challenge-response authentication)代码:auth2-chall.c中的input_userauth_info_response()函数:
1 | u_int nresp; |
实现代码
首先 sizeof(char*) = 4 nresp 可控
1 |
|
这个 时候 我们的 response 数据很小,从而可以结合其他漏洞对 这个程序进行工具
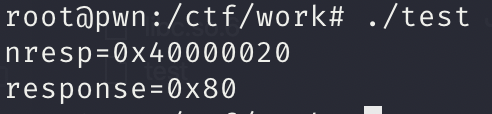
关键代码
1 | response = xmalloc(nresp * sizeof(char*)); |
1 | a = 0x40000020 |
- 当存在 malloc 函数的时候。如果malloc 的大小为 一个可控数值*一个实数
- 在申请大小后,有循环会用到我们申请的内存,循环的结束为我们 可控数值
- 对我们申请的内存 存入的值 是我们可以控制的
避免溢出
(1)当函数的参数类型为无符号整数时,需要对传入的参数的值进行有效判断,避免直接或者经过运算后产生回绕;
(2)不可信源的数据仍旧需要格外注意,应对来自不可信源的数据进行过滤和限制;
(3)使用源代码静态分析工具进行自动化的检测,可以有效的发现源代码中的无符号整数回绕问题。
同类型
1 无符号数*2
Samate Juliet Test Suite for C/C++ v1.3 (https://samate.nist.gov/SARD/testsuite.php)

- 第27行使用 fscanf() 函数从输入流(stream)中读入数据,并在第28行对读入数据的下限进行了限制,但并没有对 data 值的上限进行限制,当第31行进行 data2 运算后赋值给 result,如果 data2 的值超过了 UNIT_MAX,则会产生无符号整数回绕问题。
修复 : 在 data * 2 之前增加一个 data < UINT_MAX/2 的判断
2 无符号数+ 一个数
CVE-2017-15056。漏洞报告在 https://github.com/upx/upx/issues/128
commit中PackLinuxElf32::PackLinuxElf32help1函数中添加在250-256行的校验:
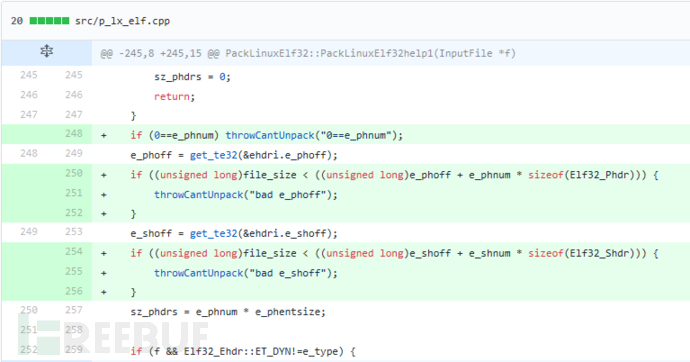
file_size是用户输入的ELF文件的大小,e_phoff, e_phnum, e_shoff, e_shnum都是ELF文件头部的字段。
值得注意的是unsigned long的大小是:MSVC下永远是32位整数,gcc和clang下32位ELF就是32位整数,64位ELF就是64位整数。
用32位UPX的话,(unsigned long)e_shoff + e_shnum * sizeof(Elf32_Shdr) 是可以溢出的,只要e_shoff足够大,让它们的和大于或等于2^32,它的值就可以小于file_size。
3 无符号数回绕
CVE-2018-6323
二进制文件描述符 (BFD) 库(也称为 libbfd)中头文件 elfcode.h 中的 elf_object_p() 函数(binutils-2.29.1 之前)具有无符号整数回绕,溢出的原因是没有使用 bfd_size_type 乘法。精心制作的 ELF 文件可能导致拒绝服务攻击。
4 题目-全球某工商的ctf网站上的ctf题(还有源码福利)
1 |
|
- Flow 函数中的 passwd_len 是
unsigned char我们可以增加 input 的长度从而绕过 第8行 - 261=5,构造261位,既可以绕过检测
5 缓冲区溢出导致安全问题
1 | int func(char *buf1, unsigned int len1, |
想把buf1和buf2的内容copy到mybuf里,其中怕len1 + len2超过256 还做了判断,但是,如果len1+len2溢出了,根据unsigned的特性,其会与2^32求模,所以,基本上来说,上面代码中的[1]处有可能为假的。(注:通常来说,在这种情况下,如果你开启-O代码优化选项,那个if语句块就全部被和谐掉了——被编译器给删除了)比如,你可以测试一下 len1=0x104, len2 = 0xfffffffc 的情况。
带符号整数边界
实现代码
当对有符号整数的操作导致算术溢出或下溢时,结果值“包围符号边界”并通常导致符号更改。
在32位整数中,值0x7FFFFFFF是一个大的正数。向其添加1将产生结果0x80000000,这是一个很大的负数。
1 |
|
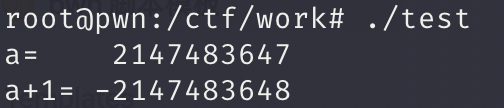
发现我们的值 发生了很大的变化
1 | 0111 1111 1111 1111 1111 1111 1111 1111 |
关键代码
1 | char *read_data(int sockfd) |
这里的 length 定义为 int 有符号 第7行 比较大小进行了加一(目的是计算 \x00 截断)但是因为是 有符号数。所以 length + 1 可能会存在 带符号整数边界 溢出。 0x7fff ffff + 1 = 0x8000 0000 = -2147483648 。从而绕过 7行判断。从而在 11 行 产生一个溢出。
- 定义的类型为 有符号数。(没有 unsigned 修饰)
- 当加一个数时,产生进位,且进位影响到
符号位,对符号位进行了修改。 - 一个
很大的正数加上一个很小的正数得到了一个很大的负数。
同类型
1
crypto/asn1/a_d2i_fp.c的 ASN1_d2i_fp()函数,该函数负责从IO (BIO)缓冲流中读取ASN.1对象。
1 | c.inf=ASN1_get_object(&(c.p),&(c.slen),&(c.tag),&(c.xclass), |
这里的 c.slen 被转化为 int 型 有符号。 在 BUF_MEM_grow 函数的第二个参数 len+want 可能会造成溢出
2
……
类型转换
通过一些强制类型转换,可以轻松地将无符号字符与有符号长整数相乘,将其添加到字符指针中,然后将结果传递给需要指向结构的指针的函数。
类型转换有两种形式:
显式类型转换,程序员通过强制转换显式指示编译器从一种类型转换为另一种类型;
隐式类型转换,编译器对变量进行“隐藏”转换,以使程序按预期运行。
实现代码
1 |
|
显示

强制转换用的 movs
因为 al = 0xffff
所以 eax = 0xffffffff
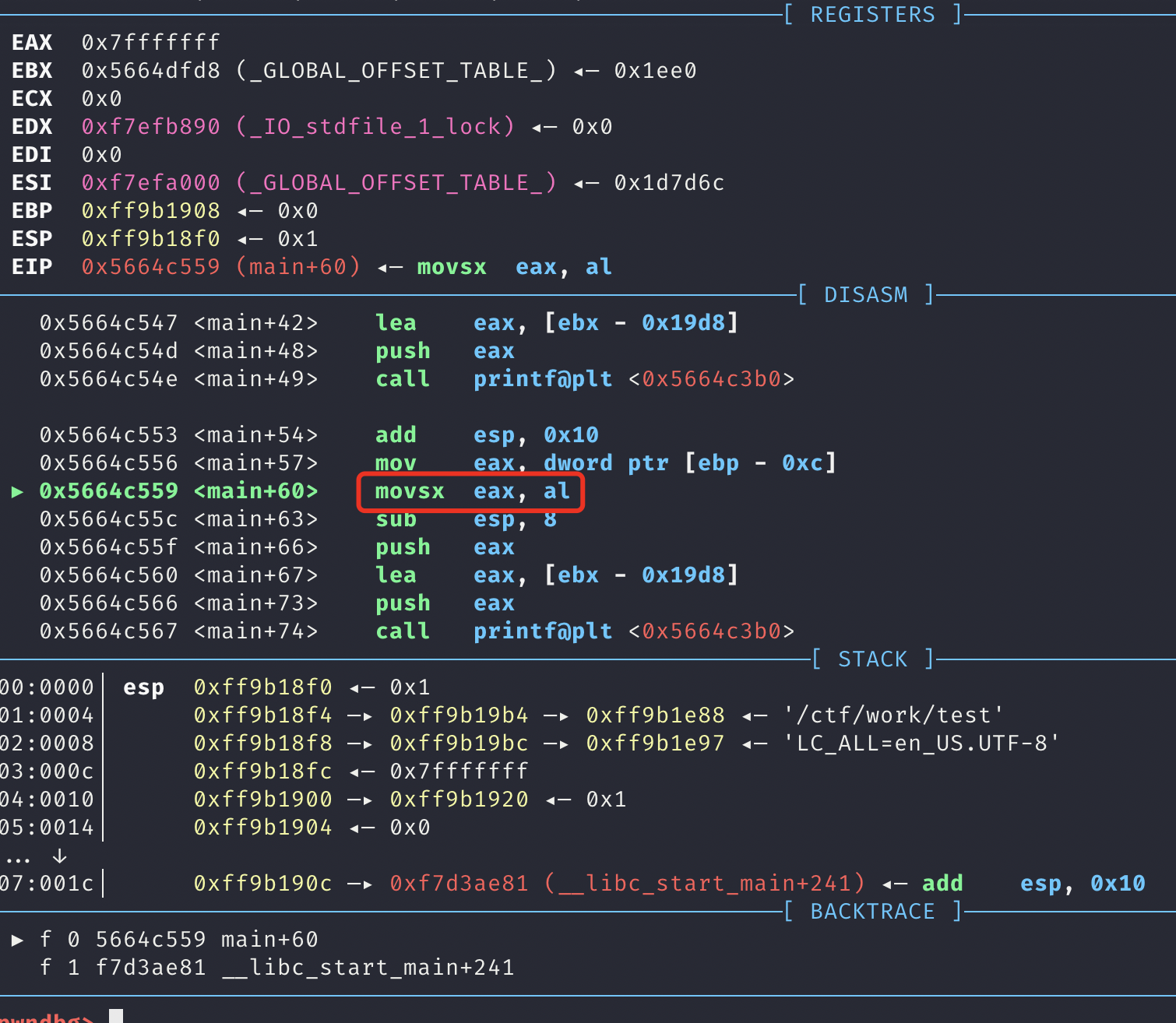
整数类型:保值
简单来说,如果新的类型能够表示所有旧类型可能的值,那么这种转换就成为保值的。
整数类型:扩展
当你将一个较窄类型转换为另一个更宽的类型时,机器会按位将旧的变量复制到新的变量,然后将其他的高位设为0或者1.
如果源类型是无符号的,机器就会使用**零扩展(zero extension)**,也就是在宽类型中将剩余高位设为0
如果源类型是带符号的,机器就会使用**符号位扩展(sign extension)**,也就是将宽类型剩余未使用位设为源类型中符号位的值。
整数类型:收缩
代码
1 |
|
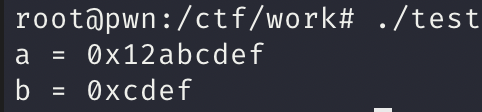
整数类型:带符号与无符号
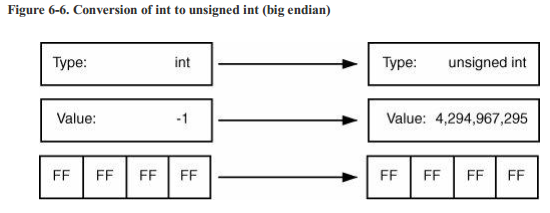
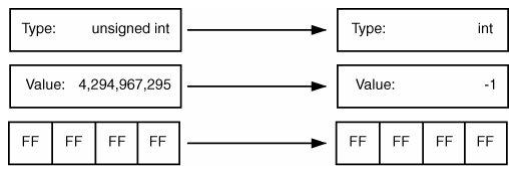
带符号/无符号转换
实现代码
1 | int copy(char *dst, char *src, unsigned int len) |
copy()函数将会看到一个非常大的len并且极有可能执行复制直到产生分段错误(segmentation fault)。
几乎所有的libc例行程序都将大小参数的类型定为size_t,这是一种和指针长度相等的 无符号类型。
这也是为什么你必须永远不要将一个负长度的参数被传入libc例行程序重,例如snprintf(), strncpy(), memcpy(), read(), 或者strncat() 。
关键代码
1 | int read_user_data(int sockfd) |
- 在定义 参数 的时候 (第3行 定义为 符号型
- 有符号参数 可控 且在后续处理中,有函数会利用到这个 参数 ( 10 行
read(sockfd, buffer, length)- 一个负长度被转换为
size_t类型,正如你所知道的,它将转换为一个大的无符号值。
- 一个负长度被转换为
技巧
函数采用
size_t或无符号整型长度参数,而程序员传递一个可能会受到用户的影响的有符号整数。适合查找的函数包括read()、recvfrom()、memcpy()、memset()、bcopy()、snprintf()、strncat()、strncpy()和malloc()。如果传入的 对应的长度参数为 负数, 在函数中会被解释成一个很大的数。
同类型
1
l0pht的反嗅探(antisniff)工具的DNS包解析代码中一个真实存在的漏洞。
http://packetstormsecurity.org/sniffers/antisniff/)的DNS包解析代码中一个真实存在的漏洞。
1 | char *indx; |
- 第一个漏洞是在这个循环中没有长度检查。如果你只是在包中提供一个足够长的域名,那么它可能写过
nameStr[]的边界。
2
研究版本1.1
1 | char *indx; |
- 第10行 count 是 int 类型 ,如果count 为 -1
if (strlen(nameStr) + count < ( MAX_LEN - 1) )可以被绕过 - 第12行
strncat函数中 count 被转化为size_t无符号类型。-1 会识别成 4,294,967,295。
3
1 | short length; |
- 定义为 有符号型。 有个上界 判断 (>1024)可以利用 负数绕过 -1 保存为 0xffff
- 然后在 6行 malloc(0) 可以实现申请 比较小的 堆块
- 第7行 read 函数的第三个参数 -1 解释为
size_t无符号 0xffff 很大产生溢出
4 截断
历史版本的网络文件系统(Network File System, NFS)的整数截断安全漏洞:
1 | void assume_privs(unsigned short uid) |
攻击者发现他们可以指定一个UID为65536,它将通过防止root访问的安全检查。但是,这个UID将被分配给一个unsigned short整数类型,并被截断为一个值0。因此,攻击者可以假定root用户的UID为0,从而绕过保护。
1 | unsigned short int f; |
strlen()函数的返回值是size_t,被转换成了unsigned short。如果一个字符串有66,000个长度的字符,那么截断就会发生,
f的值将会是464.因此,对函数strcpy()的长度检查保护就会被突破,缓冲区溢出就会发生。
大多数SSH守护进程中的一个停止显示(show-stopping)的错误是由整数截断引起的。
5 减法中的类型转换 *
1 |
|
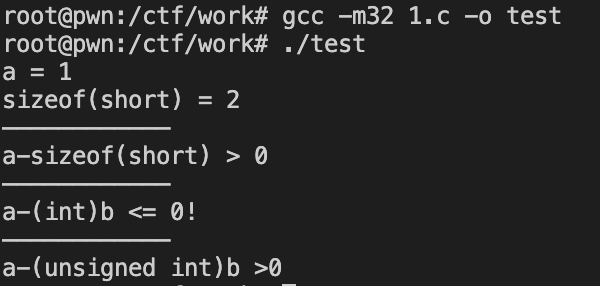
sizeof运算符的返回类型是size_t,一个无符号类型。- 所以 short 的
a-sizeof(short)- a 被升为
signed int然后被常规算术转换转换为无符号整数类型。 - 减法运算的最终类型为无符号整数类型。
- a 被升为
- 减法的结果永远不可能小于0。
- 但是如果 a减去一个符号数 就 <=0 了
6 类型转换
在很多函数 功能错误的时候 都会返回 -1
1 |
|
- Main 函数中 n 为无符号类型。
- 当我们利用到 get_int 函数时,如果输入有问题会返回-1
- 返回值 保存的 参数如果类型是 unsigned 变为一个很大的值
- 导致后面利用到这个 参数的 函数出现问题
一定要注意有无符号整数值,以免它们的对等操作数被提升为无符号整型。sizeof和strlen()是导致这种提升的操作数的经典例子。
6 整形转型时的溢出
1 | int copy_something(char *buf, int len) |
上面这个例子中,还是[1]处的if语句,看上去没有会问题,但是len是个signed int,而memcpy则需一个size_t的len,也就是一个unsigned 类型。于是,len会被提升为unsigned,此时,如果我们给len传一个负数,会通过了if的检查,但在memcpy里会被提升为一个正数,于是我们的mybuf就是overflow了。这个会导致mybuf缓冲区后面的数据被重写。
运算符
sizeof运算符
对于sizeof 类型注意
1 |
|
- 在很多时候 我们对 申请 malloc 内存返回的是指针。
- 有点时候回忘记 从而
sizeof(buffer)使用sizeof。以为会返回 1024 其实只是返回了 4 以为 buffer 是指针。 - sizeof 返回类型是
size_t一个无符号类型。
有符号数 位移
实现代码
1 |
|
显示结果
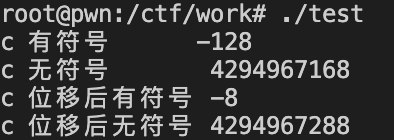
发现 我们虽然 是右移操作但是 无符号数的值却变大了
1 | 1000 0000 value before right shift |
sar助记符执行一种有符号的或算术的右移。shr助记符执行逻辑或无符号右移。
当除数为常数时,编译器通常使用右移操作而不是除法。
无符号和有符号的除法和模数操作在Intel汇编代码中可以很容易地加以区分。无符号除法指令的助记符是
div,有符号的对应指令是idiv。
同类型
1
……
优先级问题
操作符&和|的优先级
- 第一个潜在问题是位级别操作符
&和|的优先级,特别是当你将它们与比较和相等操作符混合使用时
1 | if ( len & 0x80000000 != 0) |
程序员试图通过检查最高位来判断它是否为负值。
程序员试图通过检查最高位来判断它是否为负值。他的意图就像这样:
1 | if ( (len & 0x80000000) != 0) |
然而代码实际做的是这样:
1 | if ( len & (0x80000000 != 0)) |
潜在优先级问题
- 还有一些涉及赋值的潜在优先级问题,但是由于编译器的警告,这些问题不太可能出现在生产代码中。
1 | if (len = getlen() > 30) |
代码的作者想做这样的事情:
1 | if ((len = getlen()) > 30) |
然而代码却会这样做:
1 | if (len = (getlen() > 30)) |
len 会在 if 语句后变为1或者0.如果为1,那么第二个 snprintf() 的变量就会说-29,这实际上是一个无限的字符串。